
决策树算法是机器学习中很经典的一个算法。
一、信息熵
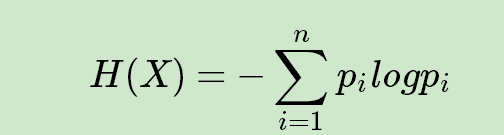
其中n代表X的n种不同的离散取值。而P_i代表了X取值为i的概率,log为以2或者e为底的对数。举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性。
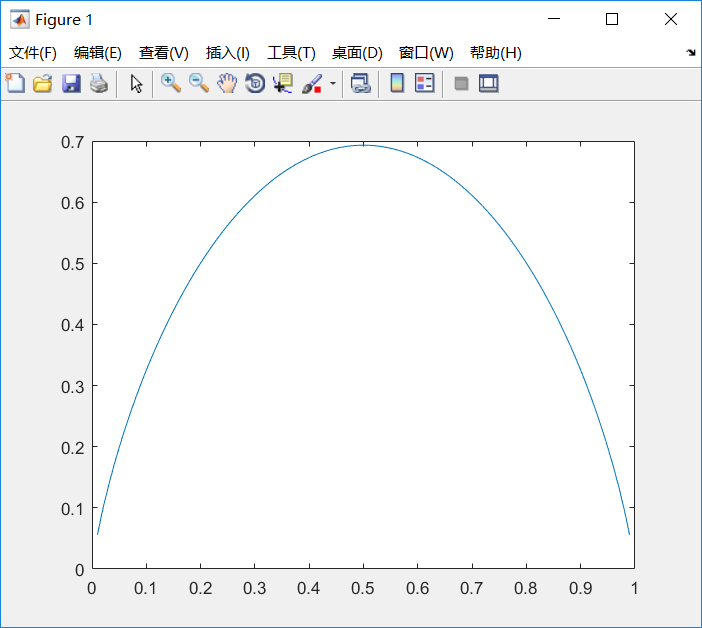
二、联合熵和条件熵

证明:
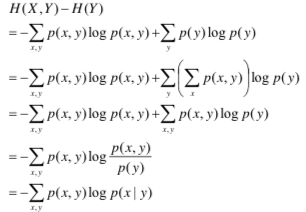
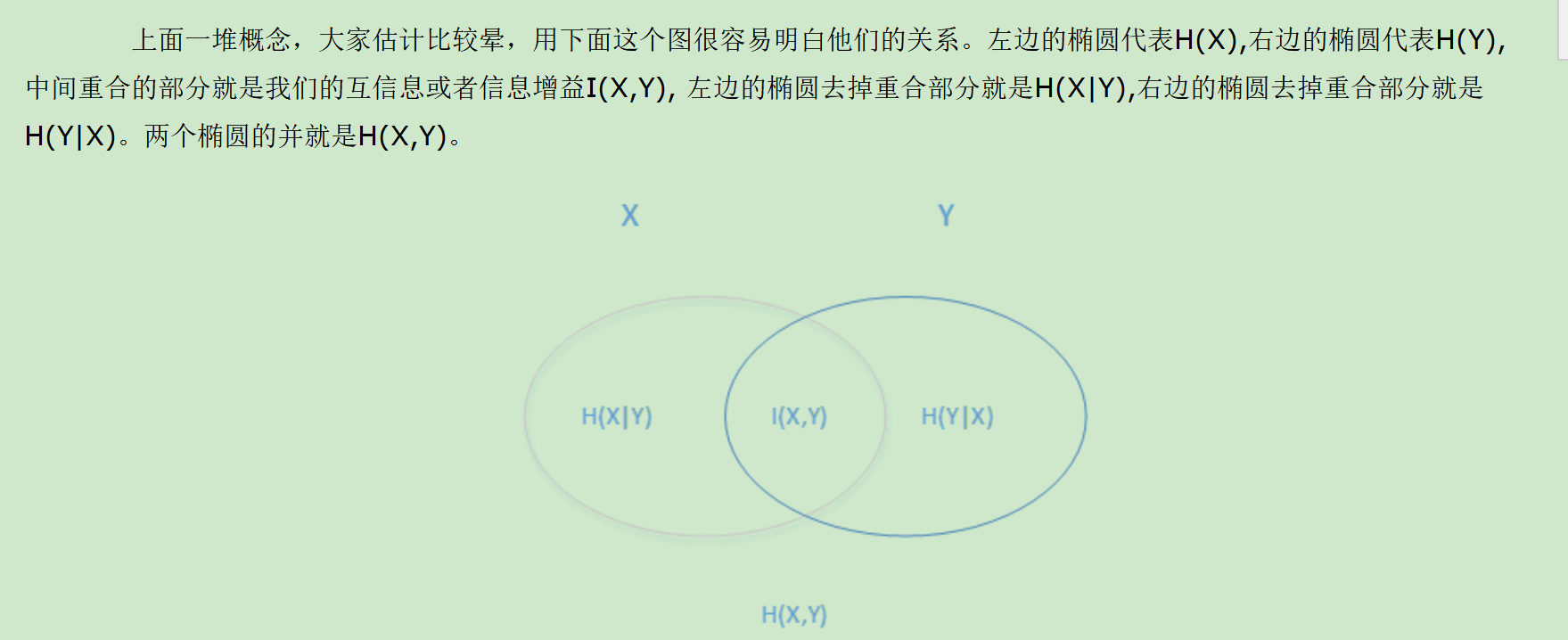
三、信息增益I(X,Y)
H(X)度量了X的不确定性,条件熵H(X|Y)度量了我们在知道Y以后X剩下的不确定性,H(X)-H(X|Y) 度量了X在知道Y以后不确定性减少程度,这个度量我们在信息论中称为互信息,记为I(X,Y) ,在决策树ID3算法中叫做信息增益。信息增益大,则越适合用来分类。
四、决策树ID3算法思路

五、特征熵


六、CART算法
不同于ID3和C4.5,CART算法使用基尼系数来代替信息增益和信息增益率,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。


七、CART算法的剪枝

八、损失函数





- 本文作者: Hbin
- 本文链接: https:/hbinfree.github.io/2021/01/10/决策树算法/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!